

Software engineers have a natural aversion to non-ascii characters. Emoji in variable names? No thanks. However, when dealing with user inputs, this aversion turns out to be a big blind-spot.
Many languages use special characters like the Spanish ñ, the German umlauts (ä, ö, ü) or the é in café. Other languages such as Chinese, Japanese and Korean completely rely on non-ascii characters.
When Glints started operating in Vietnam, this blind-spot became particularly acute. User feedback started rolling in, mostly complaints about location form elements not working as expected.
The Vietnamese Alphabet
Vietnamese, like English, is based on the Latin alphabet, but uses diacritical marks to form seven additional letters, and to indicate tonality.
The additional letters are đ, ă, â, ê, ô, ơ and ư. While pronouncing them as if they did not have any marks works in a pinch, it is not correct. They are not interchangeable with the unmarked letters.
The same goes for the tone marks: There are six tones in Vietnamese, and they are marked with five diacritics: Má (acute), mà (grave), mả (hook), mã (tilde) and mạ (dot below). The sixth one is the absence a tone mark. Tone is the curve of the pitch of the voice when speaking a word. For example, the word má is pronounced with a rising pitch, similarly to how in English, to indicate a question, the speaker's voice rises in pitch towards the end of the sentence.
It is tempting to just ignore these diacritical marks, but if we want to fix our form inputs, we certainly can not. All marks have a meaning, and omitting them will either produce a non-existing word, or a word with a different meaning. For example, the word con dế means cricket, but con dê means goat!
As the word con dế above demonstrates, the additional letters can be combined with the tone marks. So, going from the base Latin alphabet, in Vietnamese letters can have zero, one or two diacritics. That makes for a lot of potential combinations!
Input Methods
There are multiple input methods that can be used to type Vietnamese on an (English) keyboard. We'll talk about Telex here, which is the most common input one, and Vni, which is the default input method for Vietnamese on Ubuntu.
Vni
This one is pretty straight-forward. With Vni, the number- and the square bracket keys are repurposed to either write one of the new letters, or add a tone mark to the last letter. There are some variants of the exact mapping out there, but Ubuntu uses the following:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 0 | [ | ] |
|---|---|---|---|---|---|---|---|---|---|---|---|
| ă | â | ê | ô | à | ả | ã | á | ạ | đ | ư | ơ |
For example, to write dế, type d38. The 3 produces ê and the 8 adds the acute diacritic.
To write người type ng[]5i. The [ produces ư, the ] produces ơ and the 5 adds the grave diacritic to the ơ.
Installation
This comes pre-installed on Ubuntu (20.04 LTS). To enable it, go to Settings > Region & Language > Input Sources and add Vietnamese. Switch between input methods with super+space.
Telex
The more common input method is Telex, where some letter keys can be pressed twice to produce the alternate version of that letter, and other letter keys are repurposed for adding diacritical marks. The latter works because the Vietnamese alphabet doesn't use some letters like J and W, and some letters like X can not appear at the end of a word. This is a really smart system!
The exact specs can be found elsewhere, but here are some examples. To write dế, type dees. The double e produces ê and the s adds the acute diacritic. Every word in Vietnamese can only have zero or one tone marks, so the tone mark placement does not really matter, and the rules are somewhat complicated. Luckily, Telex handles this for us.
To write người (person), type nguowif. The w transforms uo into ươ, and the f adds the grave diacritic. It is also possible to type nguwowif, transforming the two vowels individually, but Telex allows the shorter uow combination because Vietnamese never uses ưo or uơ.
This may seem cryptic at first, but is actually really easy to pick up. If you deal with Vietnamese text occasionally, install Telex and give it a try! You don't have to be fast with it for it to be useful to you.
Installation
To install Telex on Ubuntu (20.04 LTS) run these commands:
apt install -y ibus-unikey
ibus restartAnd then go to Settings > Region & Language > Input Sources and add Vietnamese (Unikey). Switch between input methods with super+space.
Mistakes Where Made
When we investigated the bug reports from the user feedback, we found that we had made three specific mistakes when we were coding our forms with English input in mind:
Mistake #1: Removing Diacritical Marks
Given that diacritical marks are important for the meaning of a word, it becomes obvious that removing them is not ideal. But this is what we were doing initially: To ensure that when searching for cafe and café, the same suggestions would be returned, we just removed the diacritics from the search input and the database entries before comparing them.
This approach is flawed in two ways: First of all, it makes the search less accurate. The user is no longer able to type in precisely whether they are looking for con dế or con dê, since both options will be returned.
Also, while writing an algorithm for turning café into cafe is relatively easy, doing the same for all possible combinations of diacritical marks in Vietnamese is not. This problem is exacerbated by the fact that when it comes to diacritics, there are multiple ways to write the same thing.
Mistake #2: Not All Diacritics are Equal
Unicode and character encodings are a topic in and of themselves, but let's take a look at what is actually written to your computer's memory when you type:
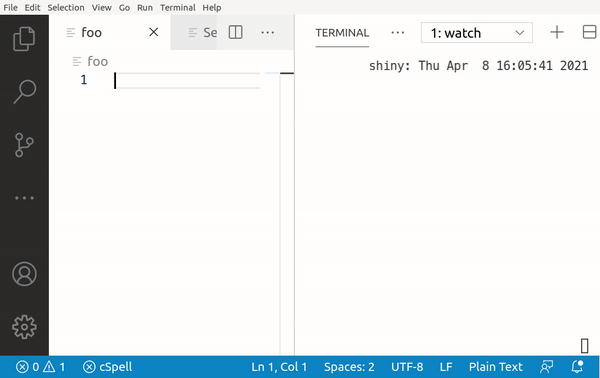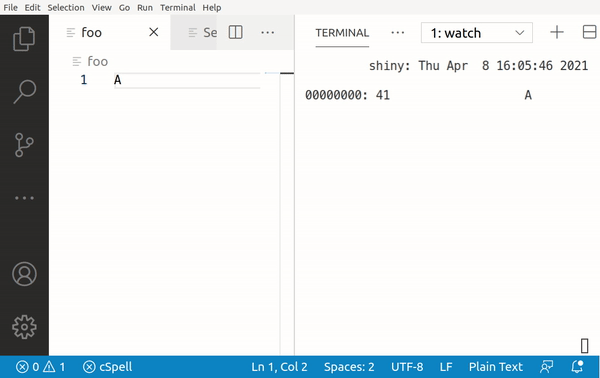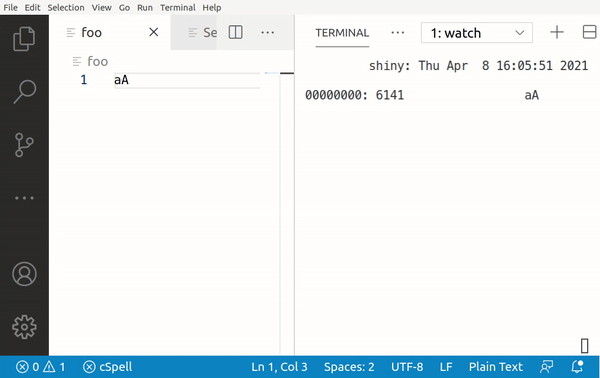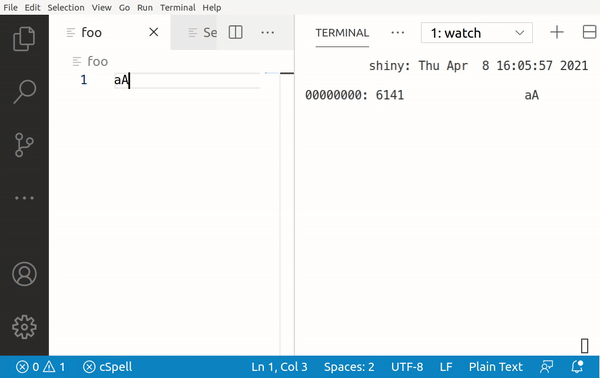
Assuming that we're using the utf-8 encoding, writing the Latin character a to a file, actually writes the byte value of 0x61 to the memory. For an uppercase A it's 0x41.
So lets see what this looks like when we try to type ậ with the Telex input system:
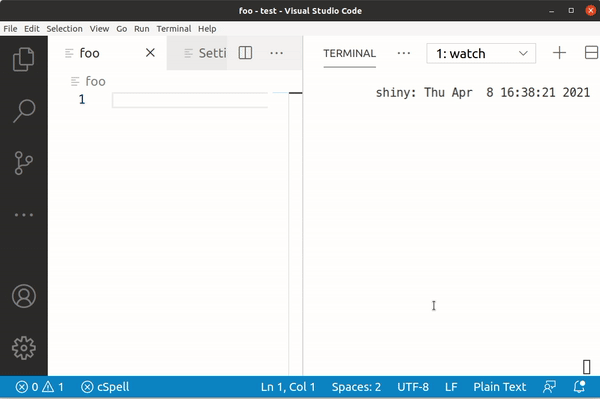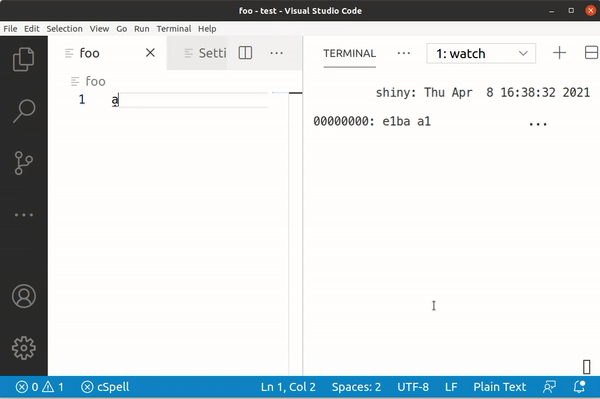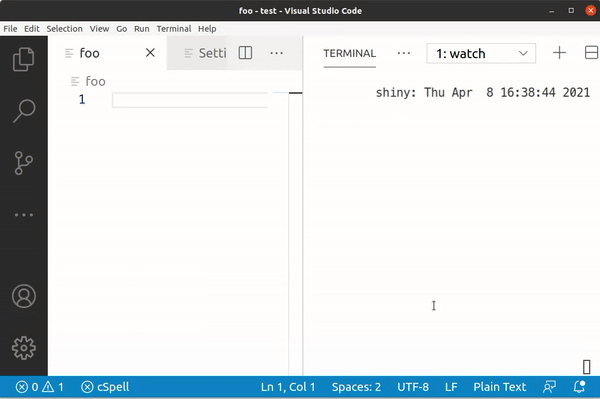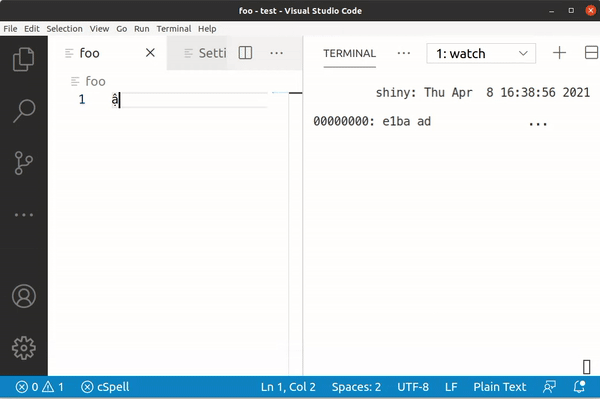
Typing a still gives us 0x61, but â is 0xC3 A2, ạ is 0xE1 BA A1 and finally ậ is 0xE1 BA AD.
However, when we try the same with the Vni input method, we see a difference:
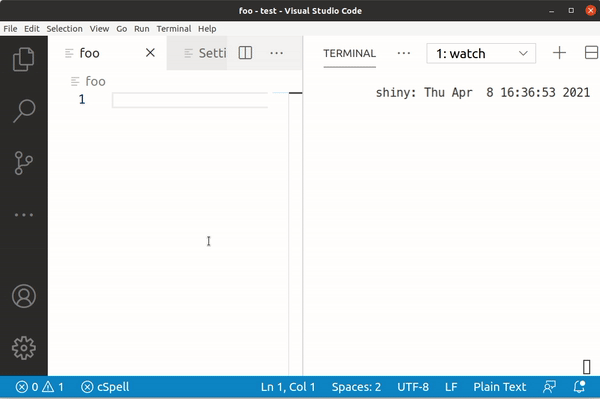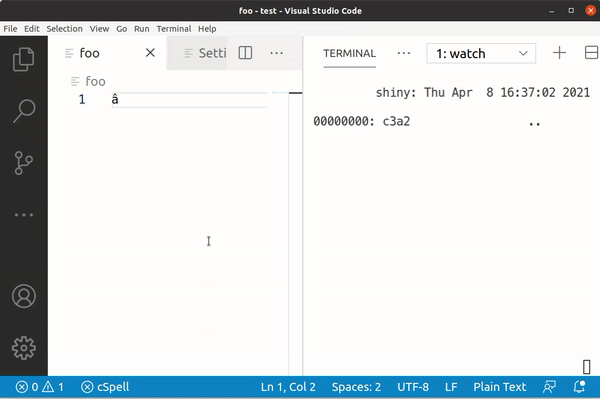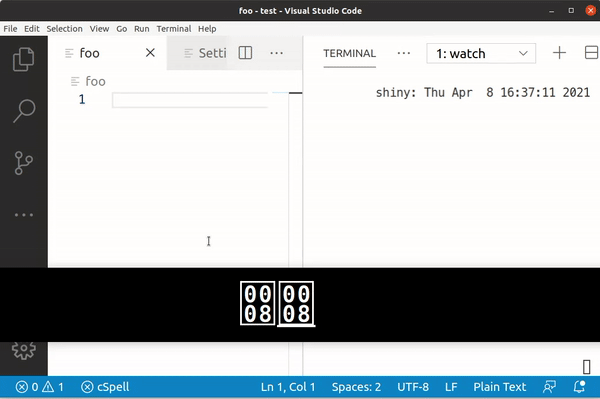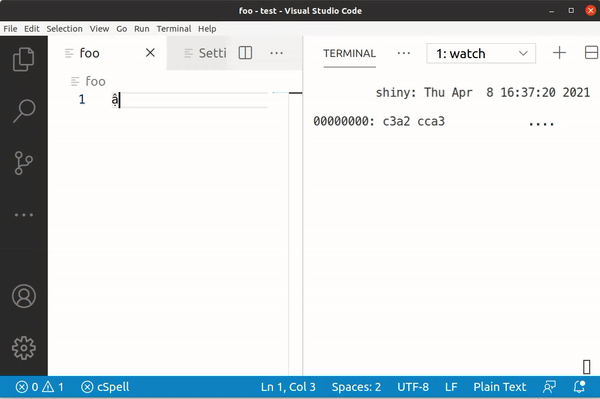
Here, typing a gives us 0x61, but â is 0xC3 A2, ạ is 0x61 CC A3 and finally ậ is 0xC3 A2 CC A3.
The difference becomes clearer when we look at the byte values next to each other:
| a | â | ạ | ậ | |
|---|---|---|---|---|
| Telex | 0x61 |
0xC3 A2 |
0xE1 BA A1 |
0xE1 BA AD |
| Vni | 0x61 |
0xC3 A2 |
0x61 CC A3 |
0xC3 A2 CC A3 |
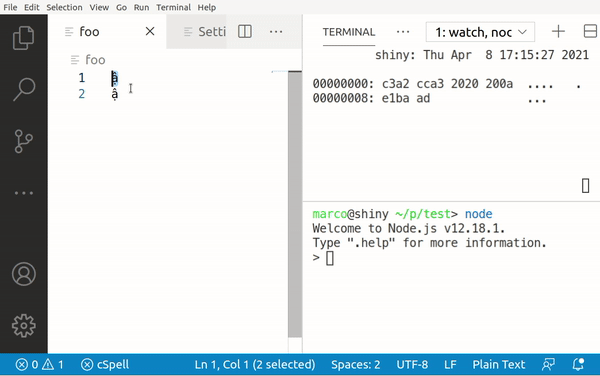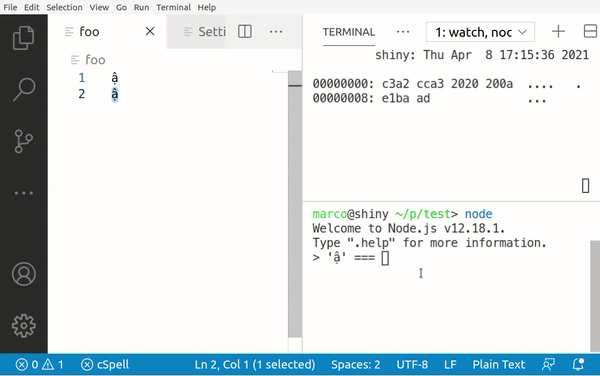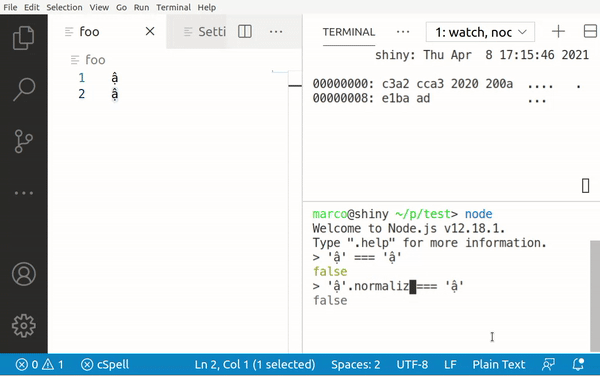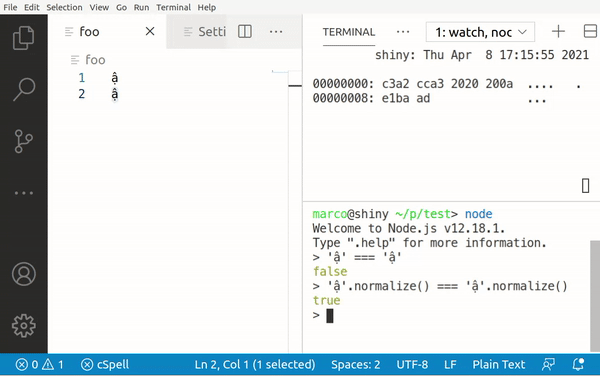
While Telex produces single characters for ạ and ậ, Vni actually produces the a and â character plus a modifier (0xA3)! This explains why some searches come up empty: If the entries being searched in have been written with Vni, but the user writes their query with Telex, the computer compares the byte values and only sees different strings.
Mistake #3: Bad Database
This one concerns the city of Dalat, or Đà Lạt as it is written in Vietnamese. For some reason, no matter with which input method the users searched for it, with our without diacritics, they couldn't find it. It was there in our database, but for some reason Sequelize just wouldn't return it.
Ultimately we found that for some reason, the entry for Đà Lạt in our database used neither Đ (D with Stroke) nor any combining mark. It was written using Ð (Latin Capital Letter Eth), which looks exactly the same, but as far as a computer is concerned, is a completely different letter.
Solutions
The fix for Mistake #3 is obvious: Fix the city names in our database by replacing all Eth chars with D with Stroke chars. However, from Mistake #1 we know that we can't fix Mistake #2 by removing the diacritics.
To fix this, we should use string normalization: This is an algorithm that is built into most modern languages. It transforms all those different byte values into one canonical version, which can then be used for comparisons.
You can find the reference for JavaScript's normalization method here: https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String/normalize
Further Reading
- A good article about the input methods: https://yourvietnamese.com/learn-vietnamese/type-vietnamese/
- The Telex Rules on Wikipedia: https://en.wikipedia.org/wiki/Telex_(input_method)#Rules
- A beautiful web book about the challenges of typesetting Vietnamese: https://vietnamesetypography.com/